Parallella Implementation of the Codelet Model
|
Contents
Objective of this project
Despite the flexibility provided by the Parallella board, dataflow based research on this platform has not been explored enough as we would expect, specially when talking about dynamic dataflow and fine-grain related programming models. To this end, this work pretends to cover this area by providing an implementation of the Codelet Model on the Parallella board (and specifically using the Ephiphany architecture) called eDARTS.
The Codelet Program Execution Model
We have already described the codelet model before. Please visit this website for a more extended version of this. However I will start by explaining the basic concepts of the codelet model.
The Codelet Program Execution Model is a way of defining parallel programs in terms of Direct Acyclic Graphs (DAG) where each node is a task(called Codelet in our model) and the edges are data or control dependencies between these tasks. Once all dependencies for a task are satisfied, the node is ready to be executed, but it will be schedule whenever all the required resources for this node are available. This is, even though a task has all its data and control dependencies satisfied, there are structural dependencies (e.g. available foating point unit, and available DMA engines) that also need to be satisfied in order for it to be executed.
A Codelet is executed until completion and cannot be stopped. This means that a codelet is non preemptive. Executing a codelet is also called firing, and after dependencies are satisfied, it is the job of the runtime to define when this happens.
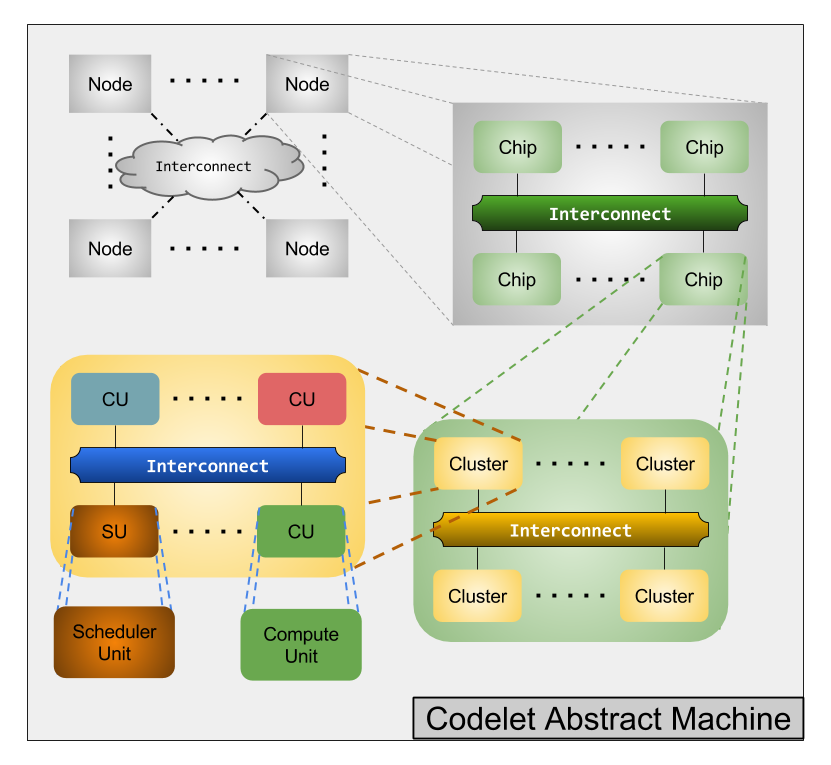
Regardless of the computer system's architecture, our program execution model uses an abstraction of it called the Codelet Abstrac Machine (CAM). However, this organization is based on what we expect future exascale architectures will look like. This abstraction groups cores into clusters, and clusters into nodes. Each core can have its own memory, and there is a shared memory inside the cluser, as well as a shared memory inside the node. Within a cluster there are two type of cores. Sychronization Units (SU), which are cores that are in charged of scheduling tasks for computation and managing resources within the cluster; and Computation Units (CU) which are in charge of executing the code within the codelets. Not all CUs are required to have the same capabilities (hetherogenity). Additionally, each CU contains a pool of ready codelets that is used to asign job to it either because the SU pushes new Codelets to the pool, or because itself or another CU pushes new codelets to the pool. The following figure shows how the CAM looks like.
The Parallella Board
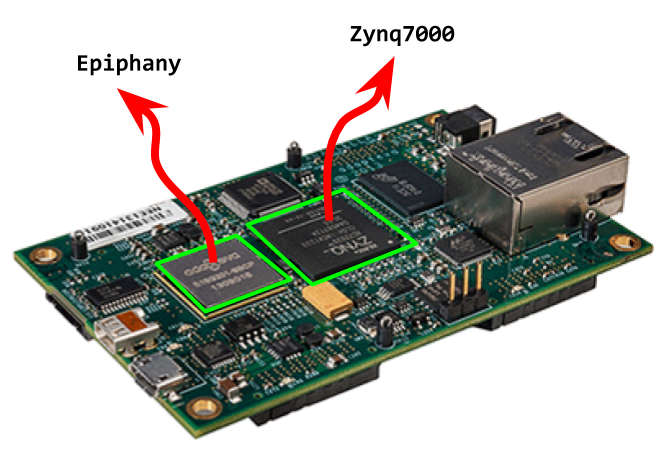
The Parallella board was developed by Adapteva in 2012 as a kickstarters project. It is a cheap, low power consumption multicore embedded system. As can be seen in the following picture, the parallella board has two different chips. One is a Zynq 7000 series SoC, and the second one is the Epiphany chip. The Zynq is made out of a dual core ARM Cortex-A9 as well as an FPGA (plus some other peripherals that are not importan to us right now) and works as a host for the parallella board. The Epiphany is a many core, scalable, shared-memory, parallel computing architecture. It is a custom architecture designed by Adapteva, and is the most important element of the Parallella Board. In the parallella board this chip is usually referred to as the device.
The eCore
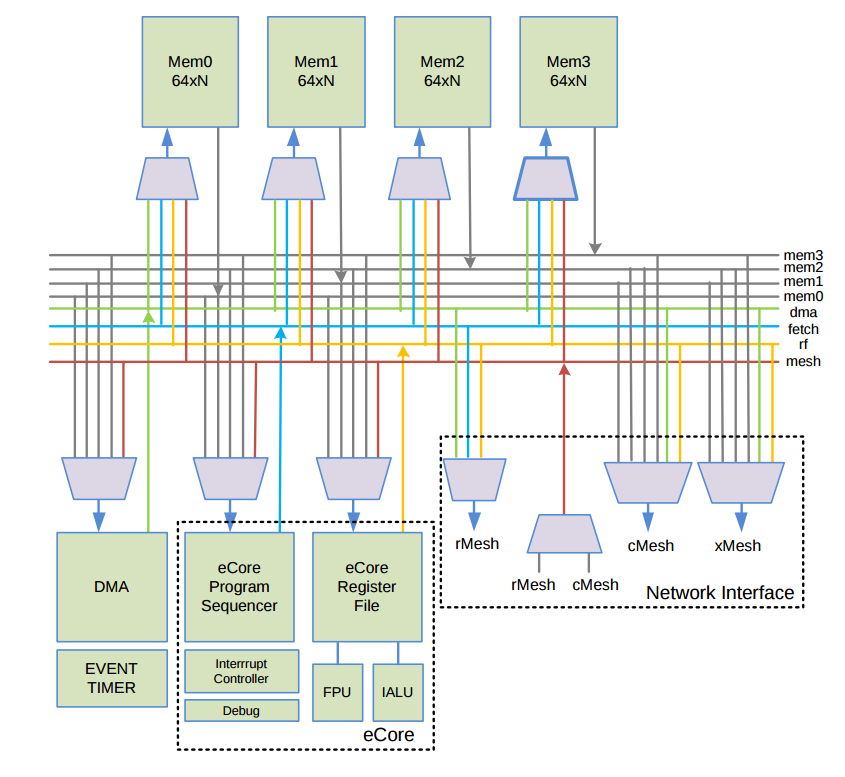
As mentioned before, the Epiphany is a multicore architecture. Each core within the epiphany (or eCore) is a super scalar, single precission floting-point enable RISC CPU. Additionally, each core has 1) four 8KB memory banks for a total of 32 KB local scratchpad memory that can be used for both code and data, 2) a 2-channel DMA engine for asyncronous data transfers that is designed to work at the speed of the NoC. and 3) a network interface that connects to a router of the NoC that will be described below. 4) Even timer registers that work as hardware counters. Following you will see a diagram of the eCore architecture taken from the Epiphany Reference Manual (page 29) .
Among the elements that is important to keep in mind regarding the eCore are:
- The 32 KB of scratchpad memory must be shared between runtime library, some elements of the standard C library, user code and data.
- There are 4 memory banks. Each of 8KB.
- There is a 64-word (Word = 32 bits) register file.
- The integer ALU (IALU) performs a single 32 bit operation per cycle.
- The single precision Floating Point Unit (FPU) executes one floating point instruction per clock cycle.
- The interrupt controller supports up to 10 interrupts and exceptions
- The branch prediction mechanism assumes the branch was not taken. There is no penalty for branches not taken.
- Load/Store instructions support Displacement addressing, indexed addressing, and post modify auto-increment adressing, with support for byte, short, word and double data types.
- Hardware counters use two timers and they can be set up to count:
- Clock cycles
- Idle cycles
- IALU Valid instructions
- FPU Valid instructions
- Dual issued instructions
- Load/Store register dependencies stalls (E1)
- Register dependency pipeline stalls
- Fetch contention stalls
- clock cycles waiting for an instruction to return from external memory
- clock cycles waiting for a load instruction to access external memory
- Mesh traffic of the loca cMesh network node
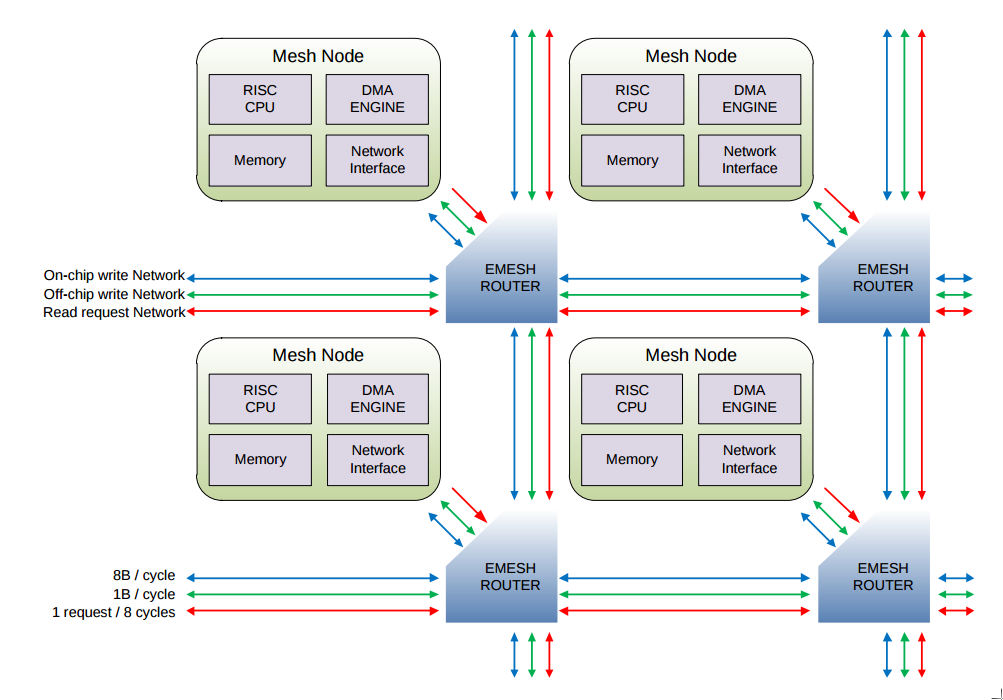
The eMesh
All cores are connected by a 2D mesh NoC, called eMesh, that is optimized for reads. Unless the core is located on the edge of the mesh, it is connected to all of its four neighbors. The eMesh is composed by three different interconnections that serves different purposes. 1) An on-chip write transactions mesh structure, 2) An off-chip write transaction structure, and 3) an on- and off-chip read requests structures. Between 2 cores it is possible to perform writes at a maximum bidirectional throughput of 8 bytes/cycle. However, a read request can only be completed every 8 cycles. For off-chip writes the throughput will depend on the available I/O bandwidth on the board. However, the chip itself has a bandwidht of 8GB/sec. The following picture taken from the Epiphany Reference Manual (page 11) describes the eMesh.
Memory organization
The epiphany has a single address space consisting of 232 bytes. This address space is word-aligned. Given that a word in the epiphany architecture is 4 bytes, it is possible to divide an address by 4. From the perspective of a core, the address space can be divided into two ranges. The first range starts at 0x00000000 and ends at 0x000FFFFF and corresponds to the local memory map. This region can be used to address the core's 32 KB scratchpad memory (which consist of 4 banks), its Interrupt Vector Table (IVT), and its memory mapped registers. The second range starts at 0x00100000 and ends at 0xFFF00000, and corresponds to the other core's local memory. Overall, there is enough space for up to 4095 cores. However, a chip with this number of cores does not exist yet. For this reason in the parallella board a subrange of this range is used for addressing the external memory that is shared between the ARM host and the ephiphany chip. The epiphany architecture has a little-endian memory architecture. Additionally, all memory accesses must be aligned according to the size of the access memory (i.e. double word alignment, word alignment, half word aligment and byte alignment).
In order to address other core's local memory we use the 12 most significant bits of the address to identify the target core. These bits are known as the mesh-node ID. 6 bits are for the row ID, and 6 bits are for the column ID. Since all the cores have their own ID, each core will have two different addresses that refer to their own memory (i.e. memory aliasing). This is, the first range 0x000XXXXX, and the second one using its own core-mesh ID 0x???XXXXX (where '?' corresponds to the core-mesh ID). Additionally,The eMesh is in charge of transfering reads and writes requests from one core to the other.
The following figure explains the memory address space and uses colors to differentiate the different ranges. It is important to notice that the external memory is within the range used for addressing other cores. As long as the number of cores is not 4095, some of this address space is used for external memory addressing. Additionally, there are two addresses that are highlighted in red that might change according to the linker script that is used. For this example we used the fast.ldf (provided with the eSDK).
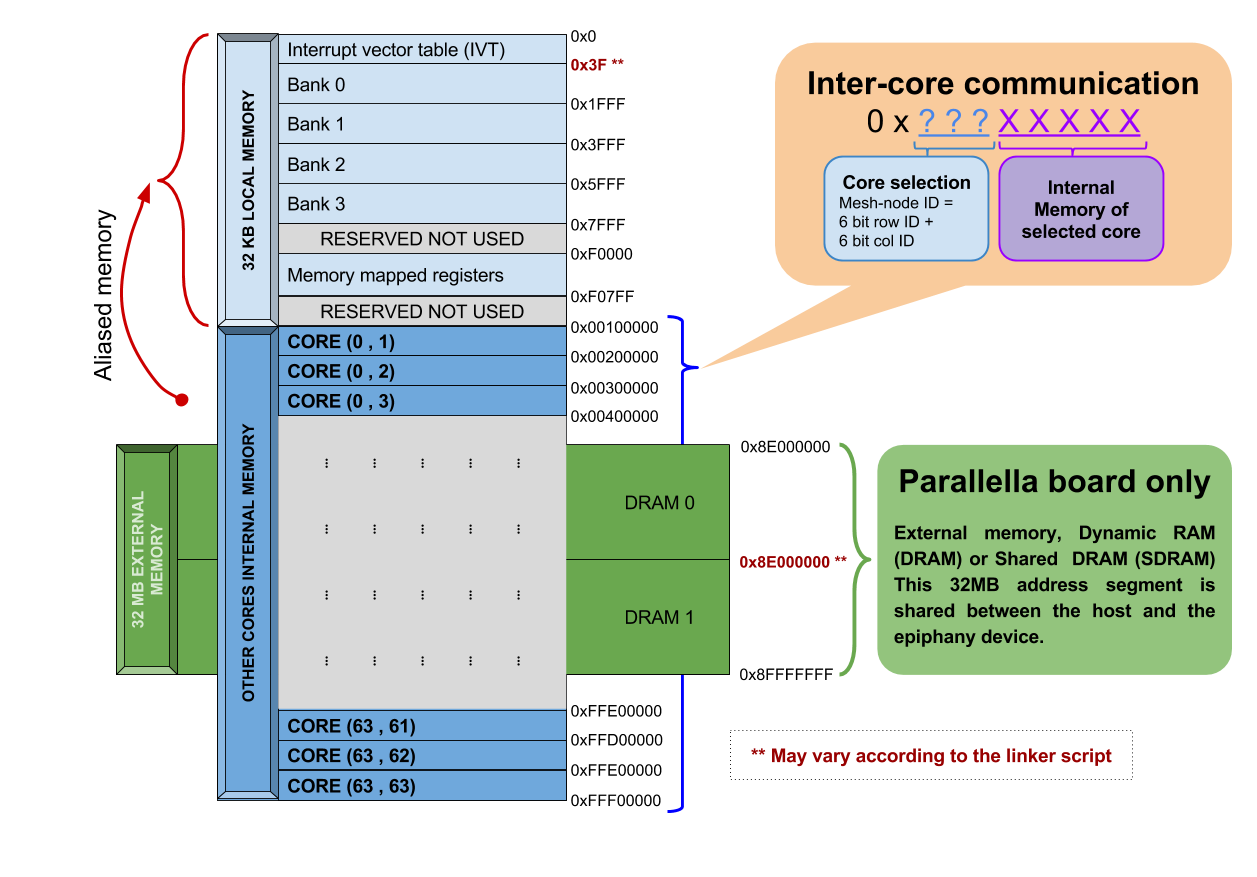
A good summary of the memory structure is also presented by the EBSP project in their Github wiki.
Another important aspect of the epiphany memory is its memory model. This is, how memory operations are organized and perceived between different cores. According to the epiphany reference manual, all memory operations that are performed within the same core follow a strong memory model. This means that the order of operations and commits to local on-core memory follow the order in which the program executes them. However, all memory operation that target memory regions outside of the core (including other cores and external memory), and which require the use of the eMesh, follow a weak memory model. This means that memory operations that have a certain order in code, might be perceived differently by other cores, or by the memory itself. To say this differently, while the core executes consecutive loads and/or stores in a certain order, it might be possible that this order changes throughout the eMesh communication and so this operation might end up being commited in a different order. There are only three guarantees regarding the order of this operations (Taken from Epiphany Reference Manual (page 19) :
- Load operations complete before the returned data is used by a subsequent instruction
- Load operations using data previously written use the updated values
- Store operations eventually propagate to their ultimate destination
Whenver order needs to be guaranteed, it is possible to use synchronization operations and order dependent memory sequences. However, this solution might be different when addressing memory located of cores that are within the same chip, or when addressing external memory. Some of the Epiphany ISA instructions that can be used for this purpose are: TESTSET (page 125), SYNC (Page 123), and WAND (Page 126). However, the last two instructions are labeled as LABS, which means they must be used carefully
Parallella programming
Thanks to the flexibility given by the epiphany chip. There have been multiple programming models implemented for the parallella board. Depending on your application and how you plan to distribute your workload, you have the opportunity of selecting between differnent options. Following there is a list of some of this models. Following a list of some of the examples and where to get resources from it. However, most of this information is also available in the parallella website and a list of examples that are provided with the board is here
- Epiphany SDK or eSDK: This Software development kit was the original libraries and tools provided by the parallella project. The set of tools cover all from IDE, compilation and linking, debugging, code and data movement between the device and the host, and command tools for gathering information from the device. This was the starting point of this project and so more information regarding this programming model will be provided further down below.
- CO-PRocessing THReads SDK or COPRTHR: There are two versions available. COPRTHR 1.6 and COPRTHR 2.0. The first version is open source, while the second version is not. However, it is possible to obtain the binaries. The idea behind this framework was to target the offloading of computation to hardware that acts as accelerators (Such as the Epiphany, a GPU or the Xeon Phi). This SDK was developed by Brown Deer Technology. It contains a set of tools that include, a compiler, the STDCL API (described as an API to offload computation to accelerators that leverages OpenCL), JIT compilation APIs, and others. Initially, Version 1.6 was created to provide OpenCL support for the epiphany. But version 2.0 was extended to provide an interface to the board similar to the one provided by the eSDK in addition to PThreads support for the board. Some of the improvements that COPRTHR provides are a better software memory management, better code offloading time and techniques that allow reexecution of code that is already available in the board, printf() support for the epiphany code, and others. The paper Advances in Run-Time Performance and Interoperability for the Adepteva Epiphany Coprocessor by Richie and Ross presents more information regarding this framework.
- Epiphany BSP: This library is an implementation of the Bulk Synchronous Parallel (BSP) programming model for the epiphany. Programs use SPMD programming models to offload the same kernel to multiple cores within the board and then use different data in each core. By using an identifier, each core access its portion of data.
- OpenSHMEMTODO:
- OpenMP for the EpiphanyTODO:
- EPythonTODO:
- CALTODO:
In order to develop our own runtime, it is necessary to use a framework that is designed to be low level. In this project we have used the epiphany eSDK for three reasons. First, we were more familiarized with it and we knew the limitations, Second, it is open source. Although version 1.6 of COPRTHR is opensource, this version did not intend to be used as a framework for runtime systems, however, version 2.0 is not open source and having access to the code was ideal for us. Additionally, when this project was created version 2.0 was still in beta. And third, we are not completely relying on the SDK for the implementation, but using small parts of it. There are some parts that will require modification in order to be adapted to the codelet model.
TODO: Add more information about the eSDK
Moving code and executing code from a different core
One of the requirements for the codelet model is that code can be moved an executed from different locations in memory. Since codelets are constantly moved arround the machine, we require some mechanism that allowed us to have position independent code. There are three different questions that we wanted to solve: 1) is it possible to execute code from a different core. 2) If so, what is the penalty that we have to pay when doing so, and 3) what mechanisms do we need to use to move code and make it position independent (PIC).
For the first part we created a simple code that would use function pointers to execute functions that are in a different core. The pseudocode for each core was something like this.
| Core 1 | Core 2 |
|---|
void myFunction() {
int *sumPtr;
sumPtr = (int*) 0x00102000; //Some local Address
*sumPtr = *sumPtr + 1;
}
int main() {
unsigned int *functionAddress, *sumPtr;
// We don't know where the function is but we know
// where functionAddress is.
functionAddress = (unsigned int*) 0x00103000;
*functionAddress = 0x00100000 + (unsigned int) myFunction;
// For sync purposes
myFunction();
sumPtr = (int*) 0x00102000; //Same local Address
// We wait for Core 2
while ( *sumPtr != 2);
return 0;
}
|
typedef void (*codelet)();
int main() {
unsigned int *functionAddress, *sumPtr;
// We don't know where the function is but we know
// that function address contain its location
functionAddress = (int*) 0x00103000;
// For Sync purposes we need to make
// sure the value is available
sumPtr = (int*) 0x00102000; //Same external Address
// We wait for Core 2
while (*sumPtr != 1);
// We cast this value to a function pointer
codelet externalFunction = (codelet) *functionAddress;
// We execute the function
externalFunction();
return 0;
}
|
Consider that core 1's mesh id is 0x001, and that the initial value of 0x00102000(*sumPtr) is 0. Core 1 will tell core 2 where the function myFunction() is in memory by using the location 0x00102000. We add 0x00100000 because linker will not provide the full address, but just the local address (i.e. it lacks of the mesh core ID). We use sumPtr to both know by the end if the functions execute to completion, and to synchronize the two cores. The two codes are compiled independently and the host will push them to different cores. Remember that this is pseudo code and it will not compile as it is shown here.
It is possible to execute code this way that exist on a different core. However, due to the independent compilation there are problems associated with this approach. First, functions that exist within one ELF file might not exist in the second ELF file. This means that if I call a second function within the first function, the resulting assembly instruction will be a jump to a function that doesn't exist. this means that it will get lost in some location in local memory and get into a deadlock. Second, all the code that is compiled and linked within a chip's local memory uses jumps relative to that local memory, and do not include the mesh core ID. This means that whatever function call within the function will have the same problem described before. Third, compiling files separately might cause the eSDK runtime information to change from one ELF to the other. This might have some side effects that will be hard to debug.
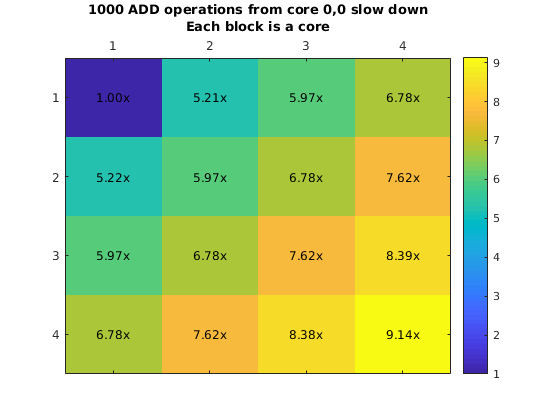
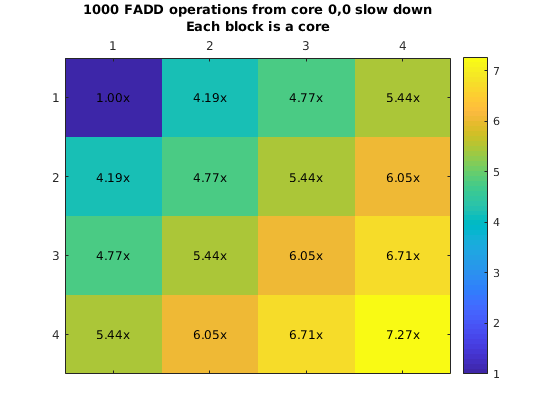
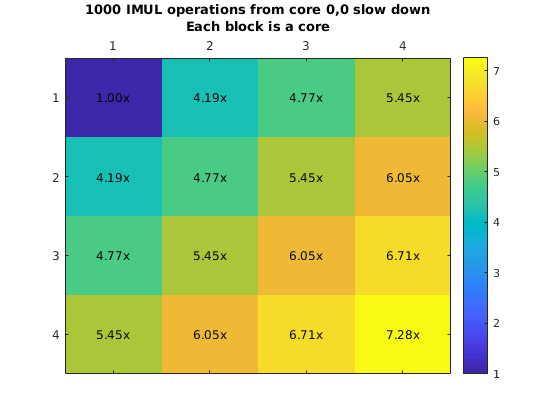
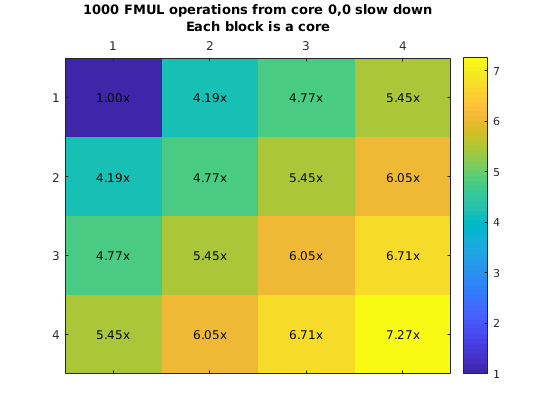
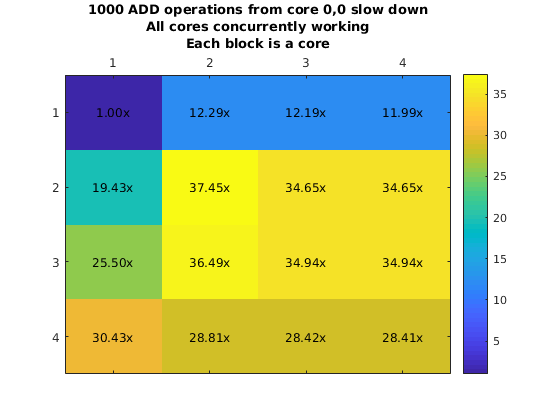
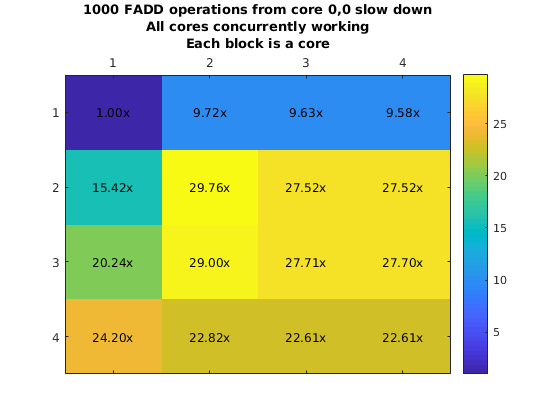
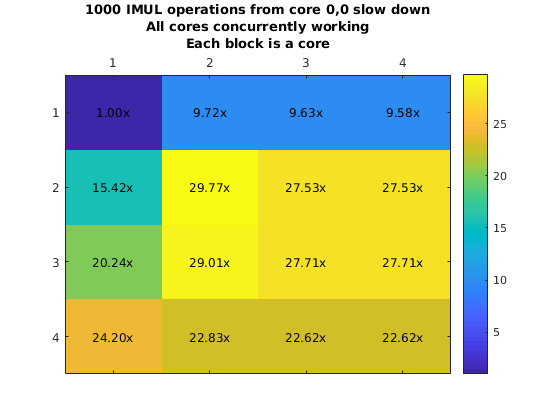
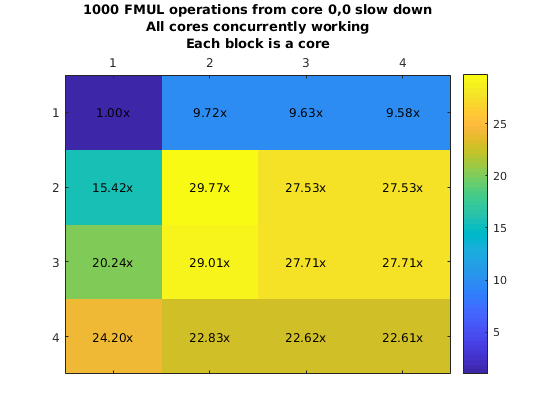
However, it was possible to run experiments using this approach. We used this approach to create a myFunction that executes a single instruction many times (e.g. Integer addition and fp addition). This loop is surrounded by a hardware clock cycles counter that will allow us to obtain how long it would take to execute this from another core. We plot the chip and the execution slowdown when placing the code in core (0,0) and executing it from all the other cores one at a time.
What is more important here is that due to the fact that the eMesh is optimized for writes, and reads take longer, it is clear that fetching code from a different core will incurr in a penalty of 4x or more. This increases with the integer add due to structural dependencies in the integer ALU unit from the loop logic. Additionally, we ran a second experiment where we will have all the other cores run the same code at the same time. This means that we are satturating the eMesh, which will increase the penalty of this operation.
Penalty increases with the row number thanks to the routing priority that the eMesh has. This means that code executed from the same row is preferable to code executed from a different row. On the other hand, even though this results look really bad (30x slowdown is a really big penalty to pay for), there might be cases that it would make sense to have core in a single core. As an example imagine a segment of code that is executed every million of iterations. But moving that code to your chip will require you to move other code that is executed more often out. It might pay off to execute that code from a different core if that means that we can keep code that is more important in our local memory.
Going back to the problem of having functions which location is fixed by the linker (and so that cannot be executed from anywhere else, or moved), e-gcc provides a flag to make all functions be position independent code (PIC). This was used for a software code caching implementation in one of the examples of the epiphany. Studying this approach can be important when developing a dynamic runtime.
Software caching (Position Independent Code)
The e-gcc compiler provided by Adepteva has a flag that enables software caching or position independent code (PIC) in the epiphany. This implementation allows the system to load and unload functions from external memory to internal memory on runtime. Otherwise, the location of code must be decided during the linking stage. Here is the blog post regarding software caching, and this repository contains examples of its use.
Software caching is a great feature, specially whenever you have a program that is larger than the on-chip memory distributed in may functions. However, for our purpose it is also a great starting point thanks to the possibility of moving code in the form of codelets. To this end, we would like to understand the current implementation of software caching to explore possible changes in our runtime.
In order to enable software caching we can use -fpic or -fsoftware-cache. Using both flags has the same effect and will add three modifications during compilation and linking:
- Create a table called Procedure Linkage Table (PLT). This table contains an entry per function available in the code.
- Change all function calls to "jump and link" (
jalr) instruction targetting its corresponding PLT entry.
- Link the code to the file
cachemanager.o which adds all the required functions and symbols for software caching to work.
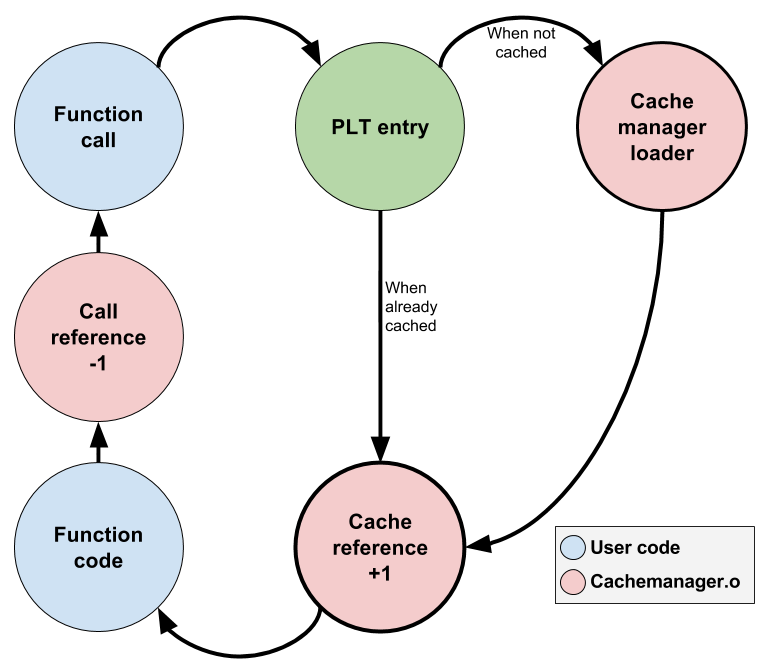
These changes modify the function call flow. The new flow is as follows:
The Procedure Linkage Table
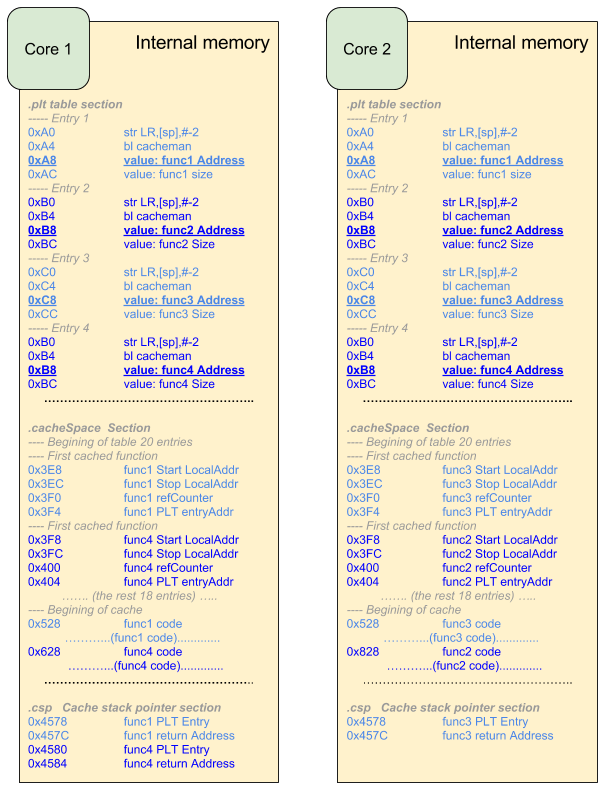
The PLT is used to have information regarding the functions that exist in the program, their size, and it is used as bootstrapping mechanism for the cachemanager mechanism. When the PIC flag is used, the compiler appends "@PLT" to all the symbols of functions that are not local. This information is processed by the linker who fills the PLT table with the information of all these functions. Each function's PLT entry is made out of 4 elements: two lines of instructions, and two data values like this:
STR LR,[SP],#-2
|
BL cacheman |
start address |
size of function |
Since all function calls are changed to the "jump and link" (jalr) instruction to the PLT entry, then every function call will go through the cachemanager whenver they are not in local memory. The cachemanager modifies the second element of the PLT entry to "BL countedcall" after loading the function to local memory. Every consecutive call to this function will result in calling countedcall which will increase the number of references that exist in the stack for that particular function and will perform the actual function call. After this function is returned, the reference is decremented and then the control flow is returned to the original function caller. PLT table is not modified back to the original version unless the function is offloaded from local memory.
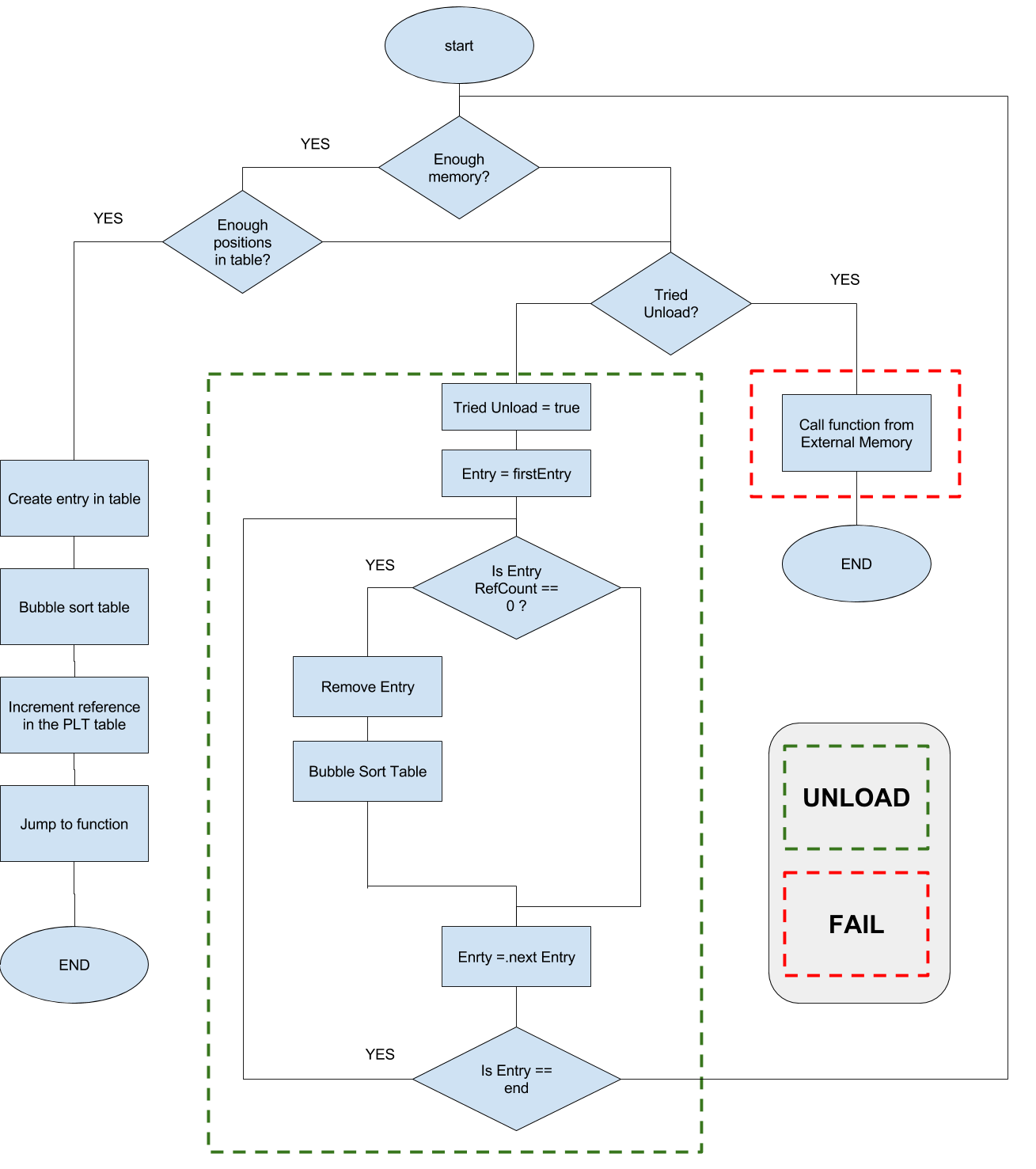
The cache manager
The cachemanager is the actual mechanism that moves code on and off chip. It uses the PLT table to obtain information of the functions, but creates a second table that is used to keep track of which functions are actually on cache memory and which functions are not, as well as the actual location in local memory. The algorithm of the cachemanager mechanism can be seen in the following flow diagram.
As mentioned before, a table is used to keep information regarding the cached functions. An example of this table can be seen below, which was taken from the cachemanager.S file provided with the cachemanager examples mentioned before. Column 1 and 2 represents the beginning and end address of the functions that are in memory. This way it is possible to find space for new incoming functions. The third column is the reference counter which helps the cachemanager decide if a function can be offloaded or not. This reference represents the number of function calls that this particular function has in the stack. Recursive functions is a good example of what could cause this number to increase. Finally, the last column is the PLT table and it is used to reset the PLT table to the original value whenever the function is ofloaded. START_ADDRESS and END_ADDRESS are used as tokens to identify the first row and empty rows in the table. The number of elements of the table is a hard limit.
| Start Address | end Address | reference count | corresponding PLT entry |
|---|
| START_ADDRESS | START_ADDRESS + | 0 | START_ADDRESS |
| START_ADDRESS + 0 | START_ADDRESS + 10 | 1 | 0xbee0 |
| START_ADDRESS + 10 | START_ADDRESS + 60 | 0 | 0xbec0 |
| START_ADDRESS + 60 | START_ADDRESS + 100 | 2 | 0xbea0 |
| END_ADDRESS | END_ADDRESS | 0 | END_ADDRESS |
| END_ADDRESS | END_ADDRESS | 0 | END_ADDRESS |
| ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ |
| END_ADDRESS | END_ADDRESS | 0 | END_ADDRESS |
| END_ADDRESS | END_ADDRESS | 0 | END_ADDRESS |
| END_ADDRESS | END_ADDRESS | 0 | END_ADDRESS |
Functions are loaded when they are called (as mentioned before). But functions are unloaded whenever there is not enough space on the cache memory or the table is full. Whenever unloading, all functions with count reference equal to zero are going to be removed and their PLT entries restored to call the cachemanager again.
In addition to this, the cachemanager creates a section in memory for its own stack and has a symbol for it called the Cache Stack Pointer (CSP). This stack is used in order to not modify the original program stack and make it transparent for the function call mantaining the ABI the same as without cache manager. Whenever a function that is in local memory is called the return address and the PLT address (which is used to find the function within the cache table) are pushed to the stack. Whenever the function returns they are pop from the stack and used to decrement the reference and return the control flow to the original caller.
The only question that is left to answer is how does the cachemanager get the return address, as well as the location of the PLT. This is done by using the LRregister (Link Register). The LR register is automatically written by the CPU whenever BL (Jump and Link) or JALR (Register Jump and Link) instructions are executed. The content of LRcorresponds to address of the following instruction after the BL or JALR instruction. This is, it is the return address, and it is the jump destination whenever the RTS instruction is called.
Thanks to the modification of the compiler where all functions calls are changed to JALR, it is possible to use this register. If you pay attention to the first entry of the PLT table, this instruction is pushing the LR register to the stack so it can be obtained either by the cacheman or the countedcall functions. The same way, the second entry of the PLT table uses BL, which allows the cacheman or the countedcall to obtain the PLT entry address.
Here is an example of how this looks in memory whenever used in two cores.
|